Les travaux de l’équipe de recherche de Denys Dutykh, chargé de recherche au Laboratoire de Mathématiques (LAMA) de l’Université Savoie Mont Blanc (USMB) portent sur une nouvelle méthode de visualisation de données. Ces travaux ont été sélectionnés pour être présentés lors de la prestigieuse conférence scientifique « Neural Information Processing Systems » (NeurIPS). Cette conférence internationale, qui se tient chaque année en décembre, a pour thème l’Intelligence Artificielle (IA). L’IA concerne, entre autres, les neurosciences, la théorie de l’apprentissage ou encore la vision par ordinateur. L’article présenté lors de la conférence scientifique NeurIPS est le fruit d’une collaboration entre l’USMB, le Commissariat à l’Energie Atomique et aux énergies alternatives (CEA), l’université du Quatar et l’université de Tempere (Finlande). Il se focalise sur un des sous-domaines de l’analyse visuelle : les méthodes de réduction de dimension supervisées.
Objet des travaux des chercheurs : l’analyse de grands volumes de données
Les travaux des chercheurs du laboratoire de mathématiques portent sur l’analyse de grands volumes de données comme, par exemple, des images digitalisées ou des signaux acoustiques enregistrés. Pour analyser ces volumes de données, il s’agit de réaliser une exploration des structures essentielles d’un jeu de données qui permettent de les classer en différentes catégories (clusters). Par exemple, classer les signaux acoustiques enregistrés permet de déterminer un certain état d’un système émetteur. Dans le cas d’une batterie de voiture électrique, classer les sons qu’elle émet avec la méthode utilisée permet de l’étudier pour, à terme, éviter les pannes.
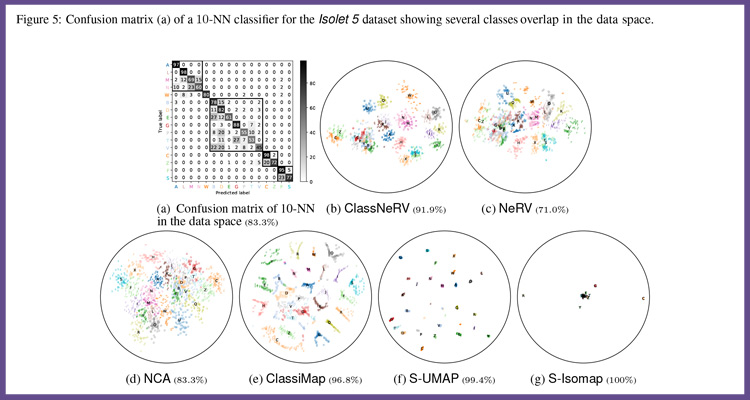
Sous-domaines de l’analyse visuelle : les méthodes de réduction de dimension supervisées
L’article présenté à la conférence NeurIPS se focalise sur les méthodes de réduction de dimension supervisées. Dans ces méthodes, l’algorithme d’apprentissage (algorithme qui donne aux ordinateurs la capacité d’«apprendre» à partir de données) est guidé par des informations complémentaires sur les données. Il traite des exemples qu’il estime probants ou non. La machine apprend alors de chaque exemple en ajustant ses paramètres pour réduire la marge d’erreur au fil des entraînements, avec pour but d’être capable de généraliser la prédiction à de nouveaux cas.
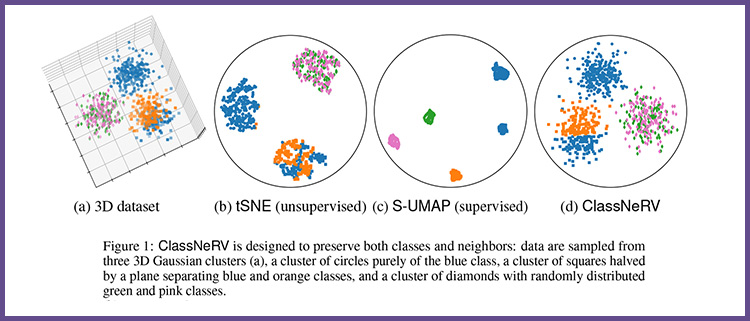
A l’inverse, les méthodes non-supervisées travaillent sur des données brutes. L’apprentissage par la machine se fait de façon totalement autonome. Des données sont communiquées à la machine sans lui fournir les exemples de résultats attendus en sortie. Par exemple, la machine arrivera à faire le tri entre des chiens et des chats, mais il pourra aussi ajouter des catégories non attendues, et classer des races inhabituelles. Il apportera dans ce cas plus d’erreurs. La méthode développée par l’équipe, appelée ClassNeRV, réussit à produire des cartes de données tirant avantage des deux mondes. Elle est extrêmement efficace pour éviter les erreurs de classification.